An LLM-based AWE program for TOEFL Independent Writing
What is AWE
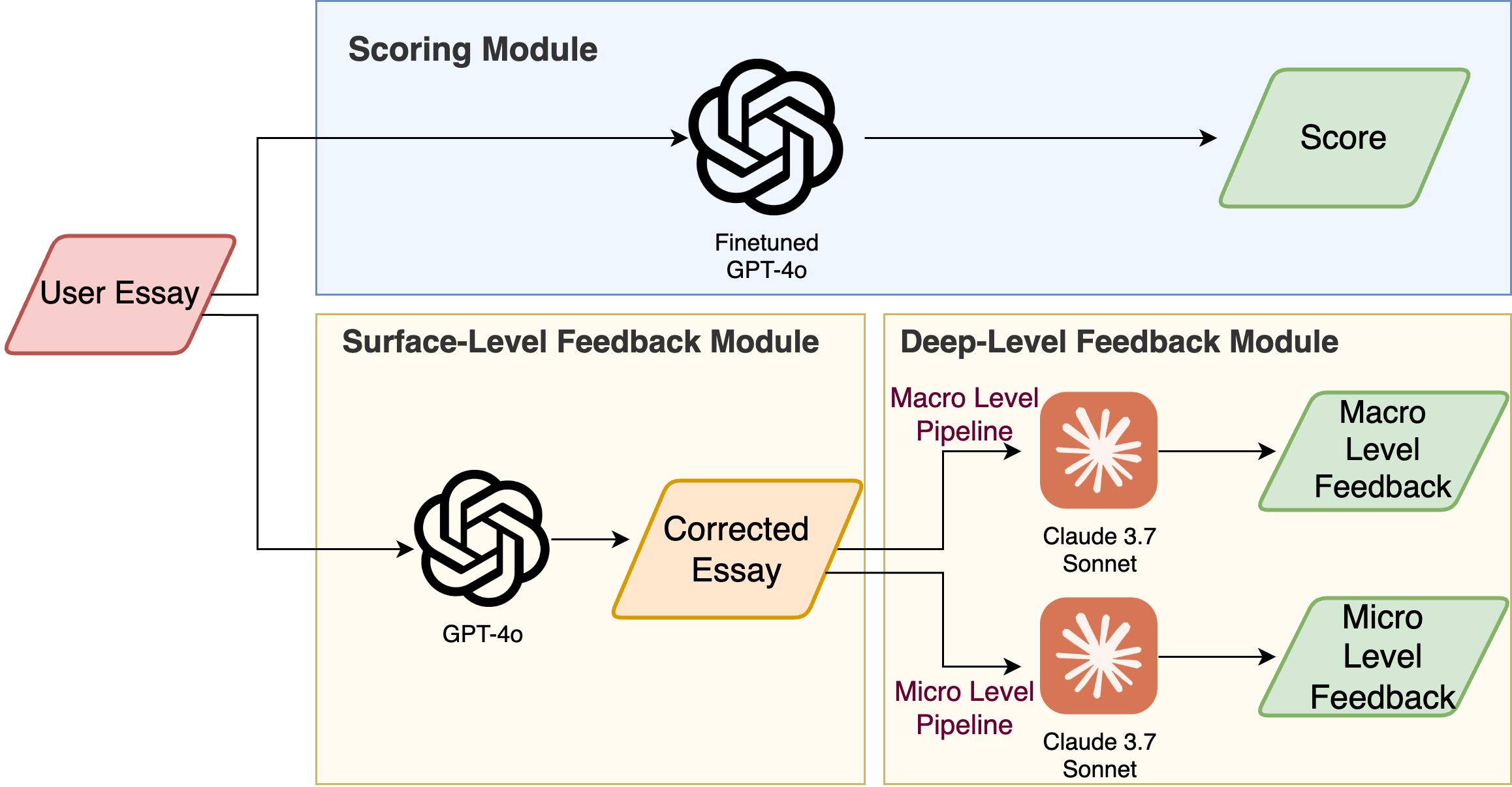
AWE is a tool that offers ETS-benchmarked scoring (from 0-5 based on previous TOEFL Independent Writing) and comprehensive feedback to argumentative essay. The tool is anonymized for several manuscripts under review right now.
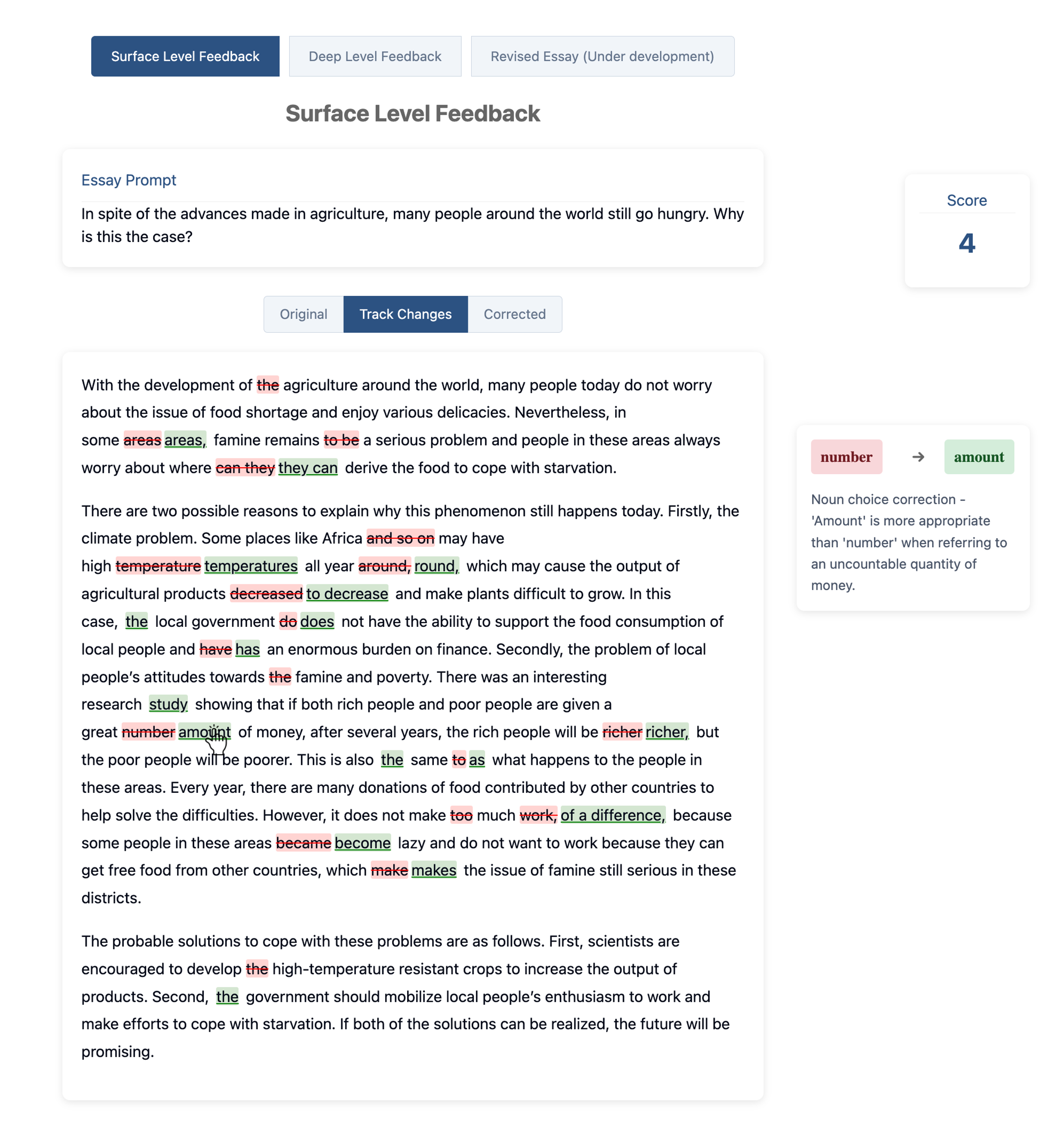
The surface-level feedback can be displayed in three modes; the figure shows the track changes mode, displaying each edit operation. The short explanation shown when the mouse hovers upon a certain edit is an idea for future work not included in the present study.
Deep-Level Feedback Page
The deep-level feedback page displays feedback comments for each paragraph on the left sidebar and micro feedback on the right sidebar when the mouse hovers over a specific text element. Highlights in different colors represent multiple traits of feedback. The page also shows a tab for “Revised Essay” (LLM-revised essay based on deep-level feedback), which is a new feature under development not included in the present work.
References
2024
Effectiveness of Large Language Models in Automated Evaluation of Argumentative Essays: Finetuning vs. Zero-Shot Prompting
To address the long-standing challenge facing traditional automated writing evaluation (AWE) systems in assessing higher-order thinking, this study built an AWE system for scoring argumentative essays by finetuning the GPT-3.5 Large Language Model. The system’s effectiveness was compared with that of the non-finetuned GPT-3.5 and GPT-4 base models via zero-shot prompting, which involves applying the model to perform tasks without any prior specific training or examples on those tasks. The dataset used was the TOEFL Public Writing Dataset provided by Education Testing Service (ETS), containing 480 argumentative essays with ground truth scores under two essay prompts. Three finetuned models were generated: two finetuned exclusively on either prompt and one on both. All finetuned and base models were used to score the remaining essays after finetuning and their scoring effectiveness was compared with ground truth scores, i.e., benchmark scores assigned by ETS-trained human raters. The impact of the variety of finetuning prompts and the robustness of finetuned models were also explored. Results showed a 100% consistency of all models in two scoring sessions. More importantly, the finetuned models significantly outperformed the base models in accuracy and reliability. The best-performing model, finetuned on prompt 1, showed an RMSE of 0.57, a percentage agreement (score discrepancy ≤ 0.5) of 84.72% and a QWK of 0.78. Further, the model finetuned on both prompts did not exhibit enhanced performance, and the two models finetuned on one prompt remained robust when scoring essays from the alternative prompt. These results suggest (1) task-specific finetuning for AWE is beneficial; (2) finetuning does not require a large variety of essay prompts; and (3) fine-tuned models are robust to unseen essays.
@article{wang2024effectiveness,title={Effectiveness of Large Language Models in Automated Evaluation of Argumentative Essays: Finetuning vs. Zero-Shot Prompting},author={Wang, Qiao and Gayed, John Maurice},journal={Computer Assisted Language Learning},year={2024},month=jul,doi={10.1080/09588221.2024.2371395},}